When navigating in urban environments, many of the objects that need to be tracked and avoided are heavily occluded.
Planning and tracking using these partial scans can be challenging. The aim of this work is to learn to complete these partial point clouds,
giving us a full understanding of the object's geometry using only partial observations. Previous methods achieve this with the help of complete,
ground-truth annotations of the target objects, which are available only for simulated datasets. However, such ground truth is unavailable for
real-world LiDAR data. In this work, we present a self-supervised point cloud completion algorithm, PointPnCNet, which is trained only on partial
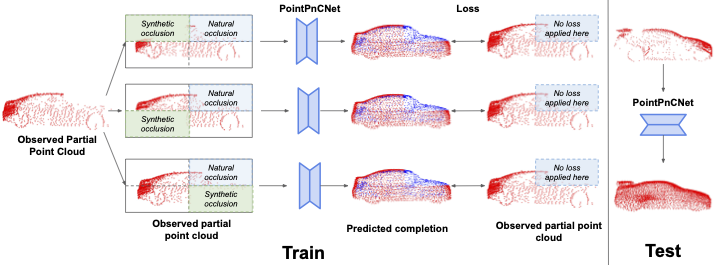
scans without assuming access to complete, ground-truth annotations. Our method achieves this via inpainting. We remove a portion of the input data
and train the network to complete the missing region. As it is difficult to determine which regions were occluded in the initial cloud and which
were synthetically removed, our network learns to complete the full cloud, including the missing regions in the initial partial cloud. We show
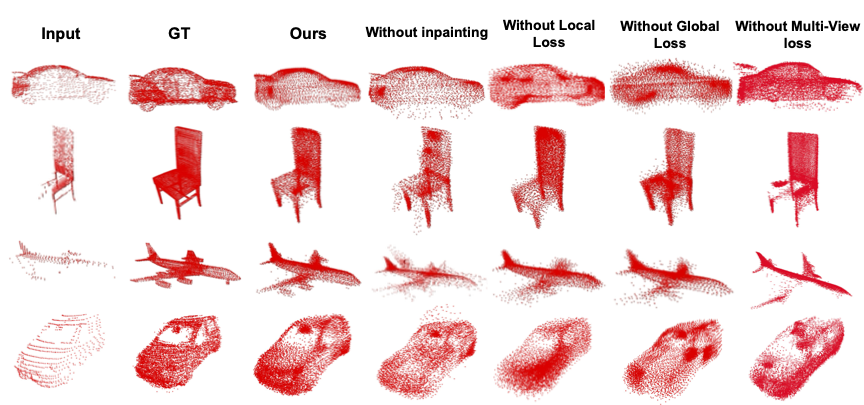
that our method outperforms previous unsupervised and weakly-supervised methods on both the synthetic dataset, ShapeNet, and real-world
LiDAR dataset, Semantic KITTI.
The point cloud completion problem can be defined as follows: given an incomplete set of sparse 3D points X, sampled from a partial view of an underlying dense object geometry G, the goal is to predict a new set of points Y , which mimics a uniform sampling of G.
In our self-supervised inpainting-based approach to learn to complete full point clouds using only partial point clouds, we randomly remove regions of points from a given partial point cloud and train the network to inpaint these synthetically removed regions. The original partial point cloud is then used as a pseudo-ground truth to supervise the completion. The network leverages the information of available regions across samples and embeds each region separately that can generalize across partially occluded samples with different missing regions. Further, due to the stochastic nature of region removal, the network cannot easily differentiate between the synthetic and original occlusions of the input partial point cloud, making the network learn to complete the point cloud.
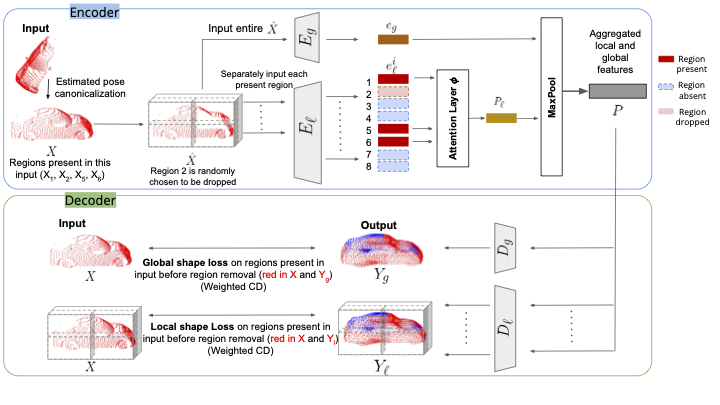
Multi-Level Encoder : Our encoder consists of multiple, parallel encoder streams that encode the input partial point
cloud at global and local levels. The global-level encoder operates on the full-scope of
the object while a local-level encoder focuses on a particular region of the object. Since
a local encoder only sees points in a given local region and is invariant to other parts of
the shape which may be missing, local encoders make the network robust to occlusions
by focusing on individual object parts separately. Global encoder further enhances shape
consistency by focusing on regions jointly with each other.
Multi-Level Decoder: Our decoder consists of multiple decoder streams that work in parallel to decode the fused
embedding P. The multi-level output generated by the network captures the details of the object at global
and local levels.
The standard loss used for comparing two point clouds is the Chamfer Distance (CD). It is a bi-directional permutation invariant loss over two point clouds representing the nearest neighbor distance between each point and its closest point in the other cloud.
Inpainting-Global Loss
This loss acts as a global shape loss, focusing on the over-
all shape of an object.
Inpainting-Local Loss
While Inpainting-
Global loss considers the entire input point cloud to find the nearest neighbor, Inpainting-Local loss differs
in that it only considers the partitioned regions to find the nearest neighbor. Thus, it acts as
a local shape loss that enables the network to learn region-specific shapes and embeddings
and focus on the finer details of an object.
Multi-View Consistency
Our method uses multi-view consis-
tency as an auxiliary loss
Datasets Used : ShapeNet and Semantic KITTI
Evaluation Metric : Chamfer Distance (CD), Precision, Coverage

This material is based upon work supported by the National Science Foundation under Grant No. IIS-1849154, and the CMU Argo AI Center for Autonomous Vehicle Research.
 Download Paper
Download Paper